19
Nov 23
14:16
If conditional entropy only goes down, why does finding out some things make me more uncertain?
Conditional probability, P(X|Y), gives the probability of x given y, as opposed to the unconditional probability P(X). Conditional entropy, H(X|Y), measures the uncertainty in x as opposed to unconditional entropy H(X). It follows from information theory that H(X|Y) <= H(X), or in other words ‘entropy only goes down (or stays the same) when conditioning on additional information’. This is fine in the relatively clean world of communication of a message, but can be a can of worms if you try to interpret this in your life with real world, everyday scenarios.
It’s somewhat non-intuitive that conditional entropy must always go down. While it’s straightforward that conditional probability doesn’t necessarily decrease — since probabilities must sum to 1 — the concept of entropy, which does not have an upper bound like probability, might seem less intuitive in this regard. Does this translate into how we measure uncertainty for real life predictions? Certainly it seems like sometimes we get more uncertain after receiving some information. In theory, Jaynes’ robot would adhere to the laws of entropy, and there is nothing to prevent Jaynes’ robot from being a human. So where does this mismatch come from?
At least one part of it is the mathematical concept of entropy being well defined versus the psychological feeling of uncertainty having a cloudy definition with lots of emotional baggage. When you find out your business partner betrayed you, or your hometown was hit by a natural disaster, you may feel less certain about the world despite receiving additional information. However, this form of uncertainty is more akin to a psychological or emotional response, differing fundamentally from the mathematical concept of entropy; a homonym.
Another problem is that it’s common to ignore priors, so we write H(X|Y) instead of H(X|YI), but in practice we are always conditioning on some prior. The closest thing we have to unconditional entropy is some entropy we compute with the principle of indifference where the number of outcomes is known but nothing else, which can never be the case for real world problems (as opposed to abstract geometric problems like balls in urns or the Bertrand paradox which is about dropping sticks onto a circle). But there is more.
An even more interesting mismatch comes from receiving information that is not consistent with your previous (prior) information. In some cases, we can condition on information that can’t possibly be true for reasons we don’t quite see yet, and this causes us to have an incorrect estimate of entropy. If you ask an insulated 16 year-old monotheist for how likely it is their god exists, many will say it is 100% because they are computing P(‘My god exists’| ‘There is an old book that says my god exists, it seems important and well written; everyone around me thinks so too’). If you ask some of them after they have been exposed to college, philosophy, or the inner workings of other religions, suddenly it will be less than 100% for a sufficiently rational student. So the entropy ‘became’ higher after conditioning on more things, and indeed, they are more uncertain.
Another real world scenario is present in the literature: What is the probability that a coin is fair (without flips)? What if the world has a just one tricky Alice, who uses a fair coin only half the time, and ten Honest Bobs, that always use a fair coin, and you don’t know who will flip the coin?
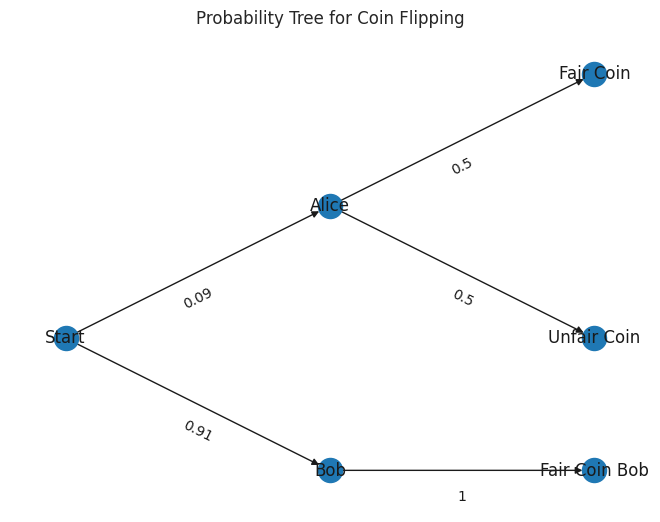
Yes, the uncertainty can increase with certain additional information here – if you know that it’s Alice doing the flipping, you aren’t certain that the coin is fair. But if a random person flips it, you are somewhat certain it will be fair because there are so many Honest Bobs. This example highlights a subtle but important distinction: while the rule H(X) >= H(X|Y) applies when considering all possible instances of Y, it does not necessarily hold for a specific instance of Y. In other words, H(X) < H(X|Y=y) is possible in certain cases, like knowing Alice is flipping the coin. That is, you can have H(X) < H(X|Y=y), for example, if you know Alice is flipping, H(X|Y=Alice) = 1. But H(X|Y) = 1/11 is still near zero since most of the time one of the many Honest Bobs will be doing the flipping. p(X=fair) = 10.5 / 11; p(X=unfair) = 0.5 / 11, so we get .27 bits with the standard entropy formula.
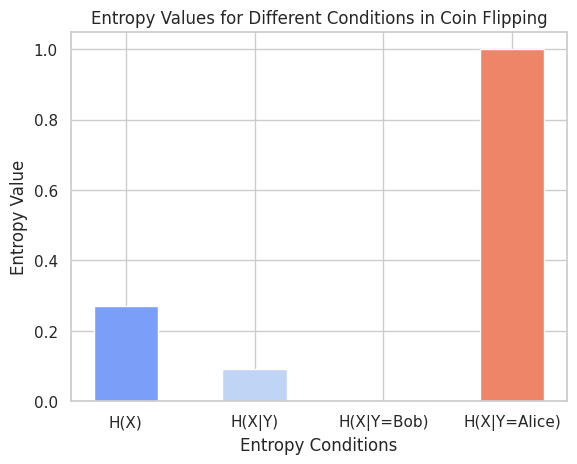
If we go back to the case of the teenager who becomes more uncertain over time, this is clearly a different mechanism by which uncertainty increases, which is more subjective. It does not consider all conditions, but just the specific Y=’There is an old book that says my god exists, it seems important and well written; everyone around me thinks so too’, so no conditional entropy rules are violated. But the key is that entropy exists only in the eye of the beholder, not as a property of the coin, or in god. And you are allowed to use a completely incorrect probability distribution (more certain than reasonable, or less certain than you should be given the conditioning). But if your distribution has no bearing on reality, you will pay the price (e.g. in bits, when using the wrong Huffman tree). Fixing overconfidence also means being less certain. One lesson here is that it’s probably best to leave conditional entropy at the door when thinking about specific conditioning, and use probability or evidence in dB instead. It’s a good thing when you realize that you’re incorrect and update your model. Jaynes invented a probability theory robot that tries to be a relatively objective by being the ‘correct’ amount of certain, using things like the principle of indifference and maximum entropy. There is another step further that Jaynes takes where he highlights the importance of the choice of hypotheses being considered beyond just the binary, but that is for another day.