16
Feb 24
09:42
Trying Out Stable Cascade Local Image Generation
Stability AI released Stable Cascade on GitHub this week. It’s very open, and allows not only inference on a number of tasks from text prompting to in-painting but also allows training and fine tuning. It’s a three stage diffusion model, and they also provide pretrained weights you can download.
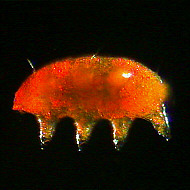
Here’s what I needed to do to get set up on Linux to play with inference. I’m running mint-xfce but it probably works the same or similar way on Ubuntu and other flavors. Here’s an example of what I generated:

Prerequisites
- Python, Jupyter
- Probably at least 10 GB VRAM like an RTX 3080, but as this is written I used 20 GB of the 24GB on a 3090 (I have 3090)
Steps
The github instructions are not super clear yet, so here’s all the steps I took.
- Clone the github
git clone https://github.com/Stability-AI/StableCascade.git; cd StableCascade - Do whatever python environment thing you prefer to install the requirements or just run:
pip install -r requirements.txt - Download the weights. If you download other variants, the default script won’t work (you can change the model .yaml files if needed, more on that later)
cd models; ./download_models.sh essential big-big bfloat16
- Run the jupyter notebook
cd ..; jupyter notebook - [Maybe optional, but I needed it] Reduce batch size to 2 from 4
– Editconfigs/inference/stage_b_3b.yamland change batch_size to 2
– Also search forbatch_size = 4in the notebook and change it to 2
(Just doing one of these two changes causes shape errors)

- Change the prompt from the ‘anthropomorphic nerdy rodent’ to the image of your dreams
- Open the jupyter notebook from the CLI output in your browser if needed. Then run the script (Click the >> button to run all or shift-enter or > for individual blocks)
Other models
You can also download other models by reading the readme in the /models directory and editing or copying the .yaml files at configs/inference/stage_b_3b.yaml and configs/inference/stage_c_3b.yaml to use the other model files (lite/small or non bfloat16). You could probably run on smaller GPUs with this method
Speed and Time
It takes about 20-30 seconds to generate two images at 1024×1024 with the big-big bfloat16 model.
It takes ~4 minutes to run the setup before generation can happen
Downloading the weights took ~30 minutes on a 500 megabit connection (about 10 GiB).
Importantly, it’s faster than the previous models. I would assume this is due to a more aggressive diffusion scheduling and getting the multiple stages of models just right (you can also consider stages as a part of the scheduling). There are 20 timesteps in the smallest (initial) model, and 10 timesteps in the second by default. These hyperparameters and architectural decisions seemed to me like they would be difficult when I first heard about diffusion models, and it makes sense they can squeeze more out of it here. I’m sure they’ve done other enhancements as well, but I haven’t even read the paper yet.
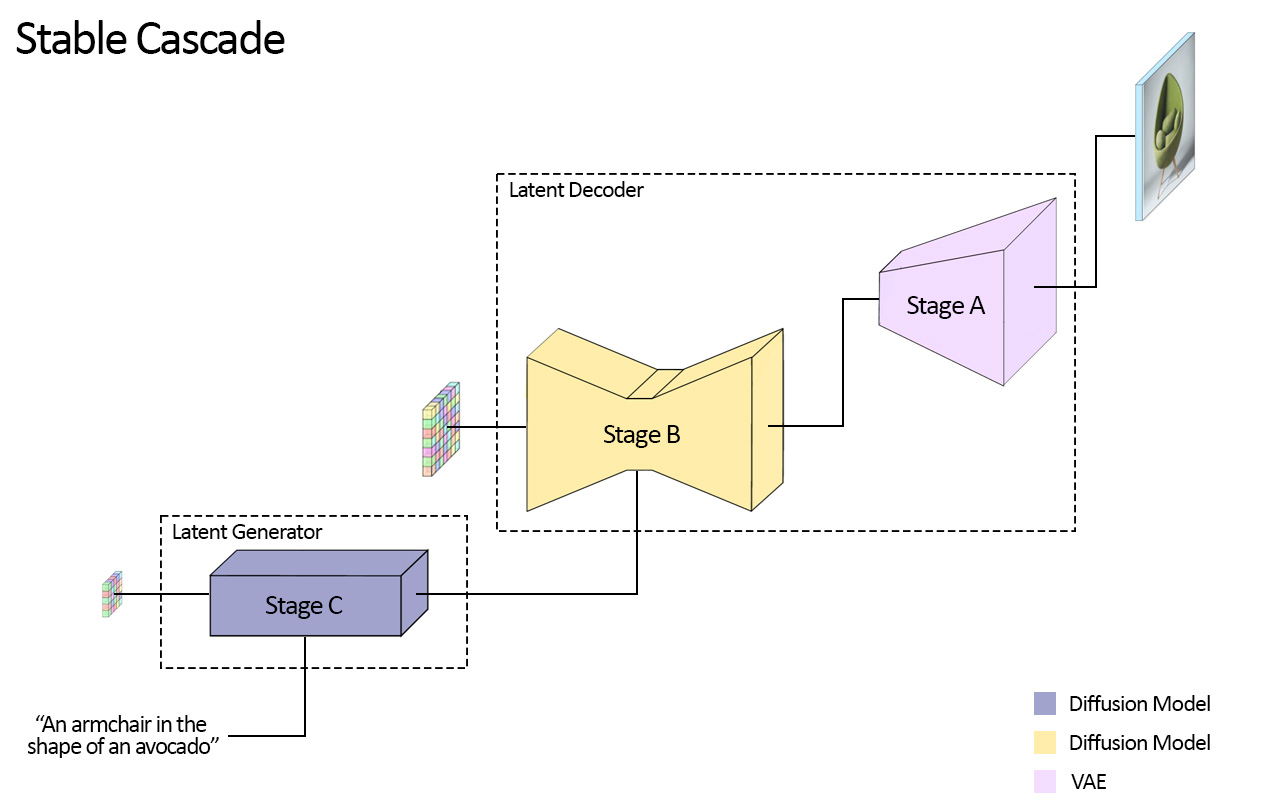
From the github description though, it’s interesting to note the first stage is actually a VAE generator that works in the reduced latent space. This is different but related to how speech models are tending towards using a sampled generator that is like a langauge model (AudioLM) to generate latents that a decoder can ‘upsample’ into the final speech audio. One of the reasons for this is that the latent space for the autoencoder in SoundStream, while reduced in dimensionality, does not use the space as efficiently as it could for speech – for example, a random sequence in the latent space is not human babble, but probably closer to noise. The generator solves this problem by learning meaningful sequences in the space.
Quality
Stable Cascade is definitely better than the previous stability AI models like Stable Diffusion XL, and the models from the free offerings they had on their website.
The model is less steerable than DALL-E 3 (although it’s hard to get DALL-E to do something exactly, you can usually get it to have most of the features you want). It’s hard to get it to draw several things at once – for example “Japanese american 150 lbs 5’11” programming on a laptop with a view of orange lisbon rooftops in the background” often only yields the Japanese American, and occasionally the laptop and the orange rooftop. In some cases, the image is noticeably distorted. There is a reason they typically request anime style and a single item in the demos. But it’s a step up from other off the shelf tools, and feels only slightly worse than DALL-E 3, which I pay ~5-10 cents per image for only slightly better images. It also has a lot of extra functionality that can be built upon, so I’m very happy to have this tool. I’d guess it handles some subjects well and others not so much. The text handling is however, significantly worse than DALL-E 3. I haven’t examined how much it censors if at all, but that’s one of the limitations that sometimes cripple reasonable requests for ChatGPT+DALL-E.

Effort
Because of the errors it took about two to four hours of tinkering to get it all working. This is longer than anyone would want, and I did other things while waiting for downloads, etc, and doing this, but is typical for me with research githubs, and part of the reason why I am documenting it. In general I liked that the github had the scripts and weights prepared, and none of the errors seemed like total blockers, especially with the issues tab on github if I really got stuck. I hope we see more repos like this from other Open companies ;).
Extra notes
- You can shift+right click to access the native browser menu to save the image output in the jupyter cells.
- There are many other demos in the ipynbs.
Appendix
Errors
Default settings allowed me to generate one of the 4 batch-sized models with the big-big model, and then all of the other 20 times I tried, it OOM’d when doing the final A stage. The only way I could work around this was to set the batch size smaller, from 4 to 2. You can edit the line in the ipynb notebook, but you have to also do it in the .yaml config file, or you’ll get some error about shapes.
OutOfMemoryError: CUDA out of memory. Tried to allocate 1.50 GiB. GPU 0 has a total capacty of 23.69 GiB of which 1022.19 MiB is free. Process 4274 has 954.00 MiB memory in use. Including non-PyTorch memory, this process has 18.79 GiB memory in use. Of the allocated memory 14.91 GiB is allocated by PyTorch, and 2.44 GiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
Redacted Bash history (in case I missed something)
1994 git clone https://github.com/Stability-AI/StableCascade.git
1995 ls
1996 cd StableCascade/
1997 ls
1998 cd inference/
1999 ls
2005 tree ..
2006 pip install requirements.txt
2007 pip install -r requirements.txt
2008 cd ..
2009 pip install -r requirements.txt
2010 ls
2011 cd inference/
2012 ls
2013 emacs readme.md
2020 cd ..
2021 ls
2022 cd models/
2023 ls
2024 emacs download_models.sh
2025 ./download_models.sh essential big-big bfloat16
2040 ./download_models.sh essential small-small bfloat16